


Emily Hanford (@emilyhanford) released (8-6-2020) an article about reading entitled:
It opens with the words:
“A false assumption about what it takes to be a skilled reader has created deep inequalities among U.S. children, putting many on a difficult path in life.”
I couldn’t agree more that a false assumption about what it takes to be a skilled reader is doing great life-harm to a great many children! However, I couldn’t agree less about what that false assumption is.
Here is her description:
“Why are so many children struggling with reading — the most basic, most fundamental academic skill? It’s a question I’ve been reporting on for several years. What I’ve found is that reading instruction in many schools is based on a belief that if children are read to a lot, reading should come pretty easily for them. Decades of scientific research on reading shows this isn’t true. Some kids learn to read easily, but many children struggle. It doesn’t matter how much they are read to or the number of books in their home. They will not become good readers unless they are taught how their written language works.”
We’ve long misunderstood the importance of reading to kids (1), but the vastly more false assumption in her description is this one:
“They will not become good readers unless they are taught how their written language works.”
This is the assumption underlying virtually everything most reading experts and pundits think about reading instruction. It’s the assumption implicit in the pedagogy of phonics, structured word inquiry, and virtually every systematic methodology and product used to teach reading. I think this is the assumption that is doing the most harm.
I realize how absurd and heretical that sounds. Please, there is so much at stake, please proceed with an open mind and consider the points I make in this article. Even if you hold on to your assumptions about “how to teach reading”, it will have been an interesting and worthwhile few minutes.
| Kids don’t need to be taught how their urinary tract works in order to stop peeing in their diapers or how their sciatic nerve works in order to realize what a pain in the butt falling is.
Kids don’t need to be taught how their ears work in order to listen to words or how their mouths work in order to speak them. Kids don’t need to be taught how a sprocket and chain work in order to pedal a bike or how the code in a video game works in order to enjoy playing it. WHY IS READING SO DIFFERENT? |
“Taught how their written language works?”
What does “how” mean? How, as in learning how to walk and talk? Babies learn how to walk and talk without needing to be taught how walking or talking works. The same is true for riding a bike, dancing, playing sports and driving a car (the attentional and physical skills, not the rules and laws). In each case, learning the skill does not require being taught how it works.
The same is true for modern digital toys and appliances. Kids learn how to play all kinds of intricate software-based games without understanding how they work. Kids learn how to use wondrous modern devices like smartphones, tablets, computers without understanding how they work.
We learn how to coordinate physical behaviors through live practice. We learn to understand how things work by constructing abstract models. The difference here is critical.
We would never insist that toddlers be taught how walking works (abstract knowledge models of neurology or biomechanics of bones, muscles, balance, momentum) to become good walkers. We would never insist they be taught how talking works (linguistic distinctions and how they relate to complex tongue and larynx movements) to become good talkers. We would never insist they learn the intricacies of a programming language or the semiconductor physics or how microprocessors work before playing a video game or using a phone, tablet, or PC. Why is this not true for learning to read?
Why must children be taught how written language works in order to be able to read?
It’s not just that’s its complex. Learning to coordinate and automate the high-speed sub processes and behaviors involved in walking or talking is far more complex. It’s not just that it’s artificial, because bikes, video games, phones, tablets, and computers are all artificial. So, what is it about “written language” that requires children to be “taught how it works” to use it?
Our written language does not phonetically represent our spoken language. Because the letters of our code do not represent single sounds, rather many, our teaching methodologies are designed to train brains to interpret the sounds of letters by abstractly recognizing the patterns in their sequences. Learning to recognize, differentiate, and disambiguate letter sounds by applying previously learned abstract pattern processing is super unnatural. Nothing like it in the pre-reading history of a child or of our species. But it’s not just that we must learn to abstractly interpret code patterns, it’s that we have to learn to interpret code patterns by way of the arbitrary authority and convoluted legacy effects of the historical accidents and negligence that instantiated the patterns.
Learning to read English is an artificially–complex and unnaturally-confusing brain processing challenge.
Recognizing unfamiliar words depends on knowing how to interpret the patterns of letters within words.
Bear with me a while as we establish a foundation for understanding why English writing is so confusing, and how that confusion causes today’s “Science of Reading” to assume that beginners will not become good readers unless they are taught how their written language works.
这些话对您“说”了什么吗?
Zhèxiē huà duì nín “shuō”le shénme ma?
Translations: “Do these words “say” anything to you?”
WORDS DON’T SAY ANYTHING.
Unless you’ve learned to interpret (read) those codes they don’t say anything at all. All of the letters or characters used to write words, including t-h-e-s-e, are elemental technological artifacts. These characters are as technological as the billions of pits on a CD or the millions of ones and zeros in a digital music file – and, they are just as silent and meaningless without the right kind of machinery to interpret and read them. Just like with the Chinese characters above, if you can’t read them you could look forever at the microscopic pits of a CD or the lines of code in a digital music file and never hear anything. Without a machine to recognize, decode, interpret, process and “play the sounds” (produce-amplify the audio we hear) CDs and music files would be completely silent.

The exact same thing is true for this c–o–d–e. Your experience of my words in your mind right here and now in your mind, is just as much the workings of a machine as listening to a CD or MP3 player. Not understanding this misorients our conceptions of reading instruction.

There are two critical differences between the machine that plays written words in your mind, and the digital devices (machines) that play music you can hear with your ears.
One difference is that the “written word player” (including the one that is currently creating your experience of these words) is not constructed of electronic chips and wires. It’s constructed of an artificially organized network of neuronal pathways that have been instantiated in the brain by the process of learning to read. This artificially organized system of neuronal connections constitutes a virtual machine – one unconsciously-automatically capable of performing machine-like code processing operations with machine-like precision at machine-like speeds. It recognizes the elements of the ABC code and performs letter-sound-spelling pattern recognition routines to identify or fabricate/assemble in the case of unfamiliar words, the internally experienced simulations of words we call reading. See “The Brain’s Challenge” for further explanation.
| CD / MP3 PLAYER | WRITTEN WORD PLAYER |
|
|
The other difference, is that the codes created for use by computers, music players, set-top boxes, and other smart devices are created by and continuously improved by highly skilled computer scientists, engineers and programmers. They have been very carefully designed to efficiently fulfill their encoding, transmission, and decoding purposes. There is no ambiguity about the elemental meaning-value of a pit on a CD or a binary 1 in an MP3 file. The codes and their encoding and decoding processes were co-designed to work efficiently together.
In contrast, our English writing code was developed by scribes who had no conception of anything remotely like computer science or software programming. They had zero knowledge of neuroscience, linguistics, phonology, early childhood development, psychology, or cognitive processing. Utterly ignorant of all these domains, the scribes most responsible for developing what would become English writing never gave a thought to how future generations of children would learn to read.

These scribes considered English a “patois” (a peasant language). As such, they believed that preserving the integrity of the Roman alphabet for its use with French and Latin, the languages used by “important” people, was far more important than caring about what would become of writing in English. Therefore, when faced with the daunting challenge of representing the forty plus sounds of English with the 26 letters of the Roman Alphabet they came up with the bizarrely arbitrary letter pairings and spelling patterns (ch, gh, ph, sh, th, tu, ti,…) that are a big part of what makes the English code the mess it is today (2). Beyond the bizarre pairings, there is an even more primary issue: the general inconsistency in how individual letters represent sounds. In the simple word “read”, for example, there are 270 possible letter-sound configurations (3x5x6x3).
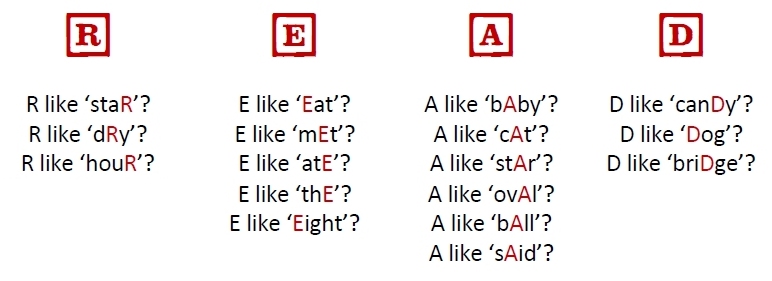
Consider this partial outline of the letter-sound ambiguity(3) of the letter “A”:
| Six Simple Sounds of the letter “A” | Six Letter-Pattern Sounds including the letter “A” |
| cake ………. letter name sound boat ………. silent dad ………. common sound soda ………. schwa ‘uh’ sound ball ………. ‘aw’ sound said ………. common ‘e’ sound |
ear ………. sounds like ‘ear’ earth ………. sounds like ‘er’ bear ………. sounds like ‘air’ sugar ………. sounds like ‘er’ arrow ………. sounds like ‘air’ hair ………. sounds like ‘air’ |
This kind of elemental code ambiguity is unique to forms of alphabetic writing. The worst of which is English. No such ambiguity exists in how our math symbols work. The number five (5) can be used in a great number of ways 5,15,25,35…50…500…5000…) but it’s always 5. It never means 2 or 3 or 7 depending on what numbers are next to it!. No such ambiguity exists in how our music symbols work. Even though a musician might “interpret” how to play musical notation, there is no ambiguity in the elemental musical symbols themselves. A C4 doesn’t sound like an F7 in some tunes and a Dm in others.

No such ambiguity exists in today’s digital codes (4). A binary one is always a one and a zero is always a zero.
The point here is that reading is a kind of mental processing that requires the brain to function artificially like an infotech machine when “playing words”. In the case of English, this infotech machine must decode a code that is, by any modern standards of code design, an utterly bug ridden mess. Thus, while in variously precarious stages of development, we are training our children’s brains to perform machine-like infotech decoding and processing using a code that is so buggy and confusing that we wouldn’t allow any of our machines to run anything like it.
WHY?
Paradigm Inertia in Reading Science
“In order to change an existing paradigm you do not struggle to try and change the problematic model. You create a new model and make the old one obsolete.”
— R. Buckminster Fuller
There are many factors that might be involved in why any particular child might be struggling with reading. She or he may have innate neurobiological learning disabilities / dyslexia. His or her early-life learning trajectory may not have provided sufficient opportunities to learn the sub-skills in language processing that reading depends on (phonemic differentiation, oral language comprehension, vocabulary, background knowledge). Potentially exacerbating any or or all of those, a child’s emotional resilience has huge effects on their ability to work through the confusion-frustration involved without “shaming out“).
While all the aforementioned issues might be involved in what is causing or contributing to reading difficulties, it’s irrefutable that the artificially complex confusion experienced during the process of learning to read is what makes the neurological challenge of learning to read so challenging. Working through the code’s confusions fast enough so that words are recognized fast enough to feed natural language comprehension is what most challenges the brains of most of the children (60+%) who struggle with reading. The code’s confusions are not the cause of dyslexia, but they certainly vastly exacerbate dyslexia as well as any and all of the other contributing factors.
| “Italian, for instance, can be learned in three months because it’s a completely regular system. Every letter corresponds to a sound. English is probably the world’s worst alphabetic language…. because there are many irregularities it is known that children will need two or more years to achieve the same level as in Italian or other regular languages.”
– Dr. Stanislas Dehaene |
Yet despite implicit agreement that decoding the code’s complex “irregularities” is what makes learning to read English so difficult, (as Dr. Dehaene confirms above), the scientists most responsible for today’s prevailing “Science of Reading” have systematically avoided connecting the code’s confusions with our children’s learning to read difficulties.
| Learning Stewards: “So what we are saying, in effect, is that the majority of our children, to some degree, are having their lives all but fated by how well they learn to interface with an archaic technology”.
Dr. Lyon: “Well, the archaic technology, if you mean by lousy teaching…” Learning Stewards: “No, the code itself.” Dr. Lyon: “Well, I see what you mean. We’re not going to change the code, I’m sure.” |
Essentially Dr. Lyon is saying: we are not going to change the code so there is no reason to think about the role of code confusion in reading difficulties (except in terms of training teachers). Because the code and its confusions are assumed to be an immutable fixture (like they have been for 500 years), the problem can’t be the code and must therefore be the lousy job teachers are doing teaching it. Note: We mean no personal criticism here. Dr. Lyon is someone we greatly appreciate for his championing of children. His response illustrates how the learning of even the best of scientists can still be disabled by their paradigms. As one of the nation’s most influential scientist / policy makers, the way he conceptualized the challenge of learning to read directly influenced government policy and academic research and indirectly influenced virtually every school in the country. Dr. Lyon wasn’t alone. The scientists most responsible for today’s reading paradigms were/are also averse to thinking about how the confusion in the code relates to the difficulties of learning to read.
Why the aversion?
| Some of us lived through this bad period in the early 70s when you had people saying: “well it’s so damned irregular that there’s no use teaching a child… look at how crazy it all is, this is why you have to focus kids on meaning because it’s so crazy they can’t learn it”.
If you come in starting to throw the complexities of English at those of us who have been in these wars that’s the worry you are going to kick up. You are talking to people who have been badly burned. – Dr. Keith Stanovich, Canada’s Research Chair of Applied Cognitive Science |
What Dr. Stanovich (also a brilliant scientist we are grateful for) is saying, like so many others, is in effect: talking about how complexly confusing the code is is what led to whole language – it’s what has perpetuated the reading wars. After all those wars and finally winning the scientific argument that phonics is better than whole language we don’t want to go anywhere near the conversation about the code’s confusion for fear of what Dr. Charles Perfetti called the emergence of the “son of whole language”. See: Paradigm Inertia In Reading Science and Policy – Part 3: Learning Disabled Science for more on this point.
Let me illustrate this point a bit differently with an analogy… Imagine a fictional product called AlphaPhon. It’s the world’s leading English language GUI (Graphemic User Interface). AlphaPhon is the entry-level product of a company (also fictitious) named USASoft. A recent study (reported 9/2020 by Forbes) indicates that 130 million older AlphaPhon customers, due to their poor use of the product, are suffering severe economic disadvantages. Even more alarming, market-wide user tests (NAEP) indicate that more than 60% of the company’s young customers are less than proficient with AlphaPhon even after 12 to 13 years of near daily attempts to learn to use it. At serious risk of losing its future customer base and going out of business, USASoft has spent billions of dollars studying why the brains of so many users are such poor users of AlphaPhon. After decades of research, USAsoft concludes it must order yet another new user instructional model, this one will train the brains of the users to understand how AlphaPhon works.
If it worked, this analogy started to sound absurd as USASoft began to act like AlphaPhon’s problems were exclusively in the minds of its users. As if it were inconceivable that anything could be wrong with AlphaPhon, or, that if something was wrong, that AlphaPhon could be in any way changed or improved. What’s disturbing, of course, is this is exactly how we have come to think about our reading problems. How could USASoft be so blind and negligent about the usability implications of such a human-engineered human-interface product? How could we? Why have we assumed that the code – English orthography – is immutable, is a legacy product that can’t be changed?
THE CENTRAL ASSUMPTION: WE ARE NOT GOING TO CHANGE THE CODE.

Dr. Lyon’s assumption: “We’re not going to change the code, I’m sure” is a reasonable assumption. Centuries of attempts to change the code – improve the regularity of the code – have been spectacular failures. People like Benjamin Franklin, Noah Webster, Melvile Dewey, Andrew Carnegie, Theodore Roosevelt, Mark Twain, George Bernard Shaw, John Steinbeck, Isaac Asimov, Richard Feynman, Charles Darwin, John Stuart Mill, William James, Lord Tennyson, H.G. Wells and hundreds of other American and British intellectual leaders all recognized how the confusion in the code was causing unnecessary reading difficulties – they all joined efforts to fix it.
Those efforts not only failed to such a degree that the U.S. congress passed a resolution against changing the code, the efforts became so ridiculed and stigmatized (for all the wrong reasons) that today even the idea of code reform is met with the same kind incredulity as suggesting neuroscience could benefit from phrenology or that the suns goes around the Earth.
Putting aside the politics, the fundamental resistance to change is easy to understand. If we improve the code so as to reduce the confusion in the relationships between letters and sounds – so word sounds are simply a blending of letter sounds – the entire existing centuries old body of written English content would become disconnected from the future of written English content. That kind of “before and after” separation would not only make it harder for future generations to read the content written prior to the change, it would mean that everyone currently able to read English as it is now would have to go through the trouble of learning the new system. Hence, Dr. Lyon’s: We’re not going to change the code, I’m sure.
Once the developing “Science of Reading” accepted that the code is a permanent fixture that can’t be changed, it had no choice to focus exclusively on how to train the brains of beginners to deal with the code’s confusions as they are. Over the decades, it became baked into how the entire Science of Reading community thinks. @Emilyhanford and today’s current crop of reading instruction gurus carry on this tradition. Thus we come full circle back to the ASSUMPTION that underlies their assertion that “they (children/beginners) will not become good readers unless they are taught how their written language works”.
Phonics – Structured Word Inquiry – OG
Every instructional system in use is based on the assumption:
Learning to read English is so unnaturally confusing to beginners that we have to teach them to have an abstract understanding of how the system works in order for them to be able to read through the confusion and recognize words.
| Most Adults and Kids Less Than Proficient | 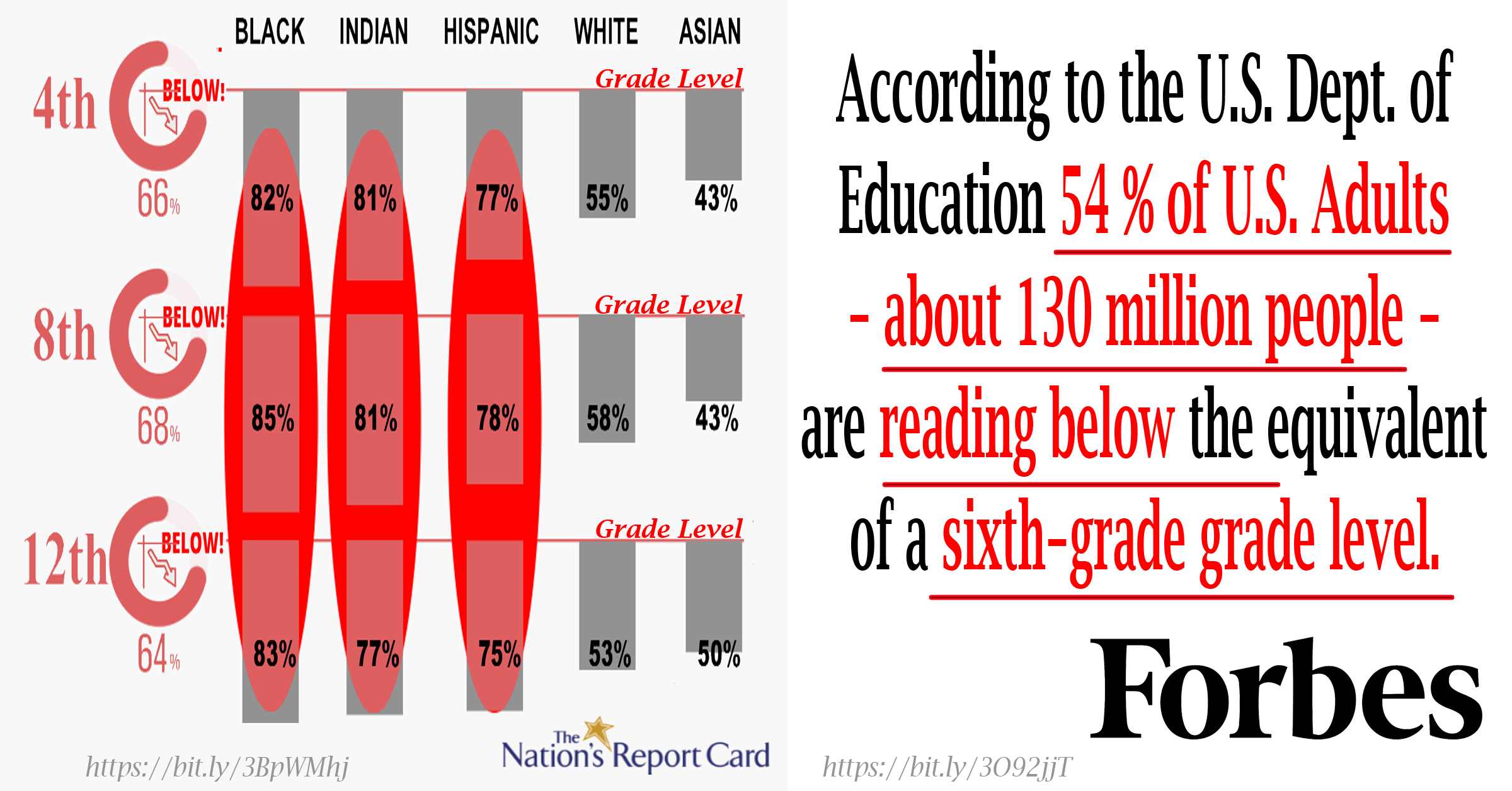 |
| Learning to Read |  |
| Steinbeck’s Appalled Agony |  |
| Flawed Assumptions |  |
| Literacy Learning: The Fulcrum of Civil Rights |
 |
| Reading Shame |  |
4) Modern digital technology is constantly dealing with the ambiguity that accompanies data corruption during transmission or due to damaged media (scratched discs for example). Many software applications have routines that disambiguate conditions and inputs. But in neither case is the fundamental elemental code the program is based on or is getting it’s inputs from itself ambiguous.
@ReadingShanahan @LouisaMoats @maryannewolf